
On this page
인문지식처리와통계
On this page
목차
- 1주차. 언어분석개론
- 2주차. Colab과 Python
- 2-3주차. 형태소 분석 개론
- 4주차. N-gram
- 4주차. Word2Vec
- 5주차. 사회 네트워크 분석(SNA)
- 6주차. 딥러닝 분석 개론
강의 계획서

교수님 소스코드 보관 공간
- 전체 공개
- 필요할 때마다 참조할 것
논문 작성 순서
- 주제(문제 의식)
- 선행 연구(1~2건)
- Rawdata(5~10줄)
- 교수님께 전달
1주차. 언어분석개론
- 자연어처리(natural language processing, NLP)
- 자연어이해(natural language understanding, NLU)
- DH에서 특히 중요
- 자연어생성(natural language generation, NLG)
- DH에서 잠정적으로 중요할 수 있음
- 자연어이해(natural language understanding, NLU)
- 언어 분석의 핵심은 "찾기"와 "바꾸기"
- 이순신을 검색하면 충무공은 누락됨
이순신 = 충무공의 의미 관계를 파악할 수 있어야 함
- 정규 표현식(regular expression)은 고급진 찾기와 바꾸기
- 이순신을 검색하면 충무공은 누락됨
- N-gram
- a contiguous sequence of n items from a given sample of text or speech

예) 행복은 너의 마음에 있다.- 1-gram(unigrams) : “행복은”, “너의”, “마음에”, “있다”
- 2-gram(bigrams) : “행복은 너의”, “너의 마음에”, “마음에 있다”
- 3-gram(trigrams) : “행복은 너의 마음에”, “너의 마음에 있다”
- 교착어로서 조사, 어미의 빈도가 높은 한국어에는 적용하기 어려운 점이 있음
- 중문을 n 단위로 나누는 경우, 각각의 token이 독립적 의미가 없는 경우가 많음
- 고전 텍스트 연구에서는 많이 사용됨
- a contiguous sequence of n items from a given sample of text or speech
- 형태소 분석(morphological analysis)

- 사전과 어법은 코퍼스(corpus)를 통해 얻음
- 코퍼스 구축은 까다로운 작업이므로 WPM 고안
- Word Piece Model(WPM)
- 하나의 단어를 내부 단어(Subword Unit)들로 분리하는 단어 분리 모델
- sentencepiece
- 언어 분석의 미래
- 하나의 단어를 내부 단어(Subword Unit)들로 분리하는 단어 분리 모델
예) 나는 은이 좋아.- [('나', 'Noun'), ('는', 'Josa'), ('은', 'Noun'), ('이', 'Josa'), ('좋아', 'Adjective'), ('.', 'Punctuation')]
- 형태소 분석의 문제점 - 한국말은 끝까지
예) 나는 선배 앞에서 멋있는 척 하는 그대를 사랑으로 감싸줄 수 없다.- 부정적인 문장인데 형태소 분석은 긍정으로 판단함
- 감정 분석(sentiment analysis)
- 감정 사전, 형태소 분석기를 통한 텍스트의 감정 분석
- 문장의 감정 판단은 주관적이라는 비판이 존재
- 사전과 어법은 코퍼스(corpus)를 통해 얻음
- 공기어 분석(co-occurrence analysis)
- 공기어(co-occurrence word) : 같은 문맥 안에서 함께 나타나 서로 밀접한 의미 관계를 갖는 단어
- 개념사 연구에 중요

인공지능
- 인공지능의 양대 흐름
- Symbolic (Ontology) : 인간의 지식을 기호로 표시하고, 이를 바탕으로 논리, 검색, 문제 표현 등을 처리
- 시맨틱 데이터(semantic data)
- RDF(Resource Description Framework)
- 온톨로지(ontology)
- LOD(Linked Open Data) : 정해진 규칙에 따라 구조화한 데이터를 웹상에 발행한 데이터
- 시맨틱 데이터(semantic data)
- Subsymbolic (Machine Learning) : 지식의 표현 없이 기계 학습과 같은 방법을 이용하여 학습, 패턴 인식과 같은 분야에 활용
- 딥러닝(deep learning)
- 지도 학습(Supervised Learning) : 정해진 답 有
예) seq2seq
- 비지도 학습(Unsupervised Learning) : 정해진 답 無
예) Word2Vec
- 강화 학습(Reinforcement Learning) : 반복을 통해 목표 달성
- 인문학에서의 활용 방안은 낮은 편
- 설명 가능한 AI(XAI, Explainable Artificial Intelligence)
- 머신러닝 알고리즘으로 작성된 결과와 출력을 인간인 사용자가 이해하고 이를 신뢰할 수 있도록 해주는 일련의 프로세스와 방법론
- 지도 학습(Supervised Learning) : 정해진 답 有
- 딥러닝(deep learning)
- Symbolic (Ontology) : 인간의 지식을 기호로 표시하고, 이를 바탕으로 논리, 검색, 문제 표현 등을 처리
- 임베딩(embedding)
- 이미지
- 이미지 → 숫자 → 알고리즘 → 숫자 →이미지
- 컴퓨터가 보는 이미지 = 숫자의 조합(RGB)
- 문자
- 문자 → 숫자 → 알고리즘 → 숫자 → 문자
- One-Hot Encoding
- 문장이 증가하면 할수록 열(단어)도 많아진다.
- 무의미한 랜덤 숫자를 배정하는 것이 아니라, 유의미한 숫자를 배정할 수는 없을까? Word2Vec!
- Word2Vec
- 단어 벡터 간 유의미한 유사도를 계산

- king-man과 queen-woman 사이의 위치 관계는 의미 관계를 반영함
- 단어 벡터 간 유의미한 유사도를 계산
- 이미지
- seq2seq
- 한 문장(시퀀스)을 다른 문장(시퀀스)으로 변환하는 모델
예) 번역기, 챗봇- 인문학에서의 활용도는 낮은 편
- 전이 학습(transfer learning)
- 하나의 작업을 위해 훈련된 모델(Pre-training Model)을 유사 작업 수행 모델의 시작점으로 활용하는 딥러닝 접근법
예) Bert / KoBert / KR-BERT / ERNIE / gpt-3 / gpt-2 / KoGPT2
- Pre-training Model
- 사전에 학습되는 모델
- 이를 활용하여 새로운 모델을 학습하는 과정은 Fine-tuning
- 하나의 작업을 위해 훈련된 모델(Pre-training Model)을 유사 작업 수행 모델의 시작점으로 활용하는 딥러닝 접근법
2주차. Colab과 Python
Colab
Colab (Colaboratory)
무료로 파이썬(python) 프로그래밍을 위한 주피터 노트북(Jupyter Notebook)을 사용할 수 있는 환경을 제공해 주는 서비스
- 로컬에 주피터 노트북 환경을 구축하기 위해서는 복잡한 과정이 필요. Colab에서는 간단한 클릭만으로 주피터 노트북 환경 구축 가능
- 연속 사용 시간이 제한되어 있음 (대략 6시간)
- 읽기 권한만 있음
드라이브로 복사버튼을 눌러 구글 드라이브에 사본 저장 가능내 드라이브 - Colab Notebooks경로에 저장- github에 사본 저장
- 우측 상단의
연결버튼을 눌러 프로그래밍을 위한 주피터 노트북 클라우드 환경을 구축- 셀에서
ctrl + Enter를 누르면 실행하고 해당 셀에 머물고,shift + Enter를 누르면 실행하고 다음 셀로 이동함
- 셀에서
런타임 - 런타임 유형 변경으로 들어가 GPU 이용 가능- 소스 코드를 손쉽게 공유 가능하다는 장점이 있음
- 로우 데이터셋은 '링크가 있는 모든 사용자로 변경'으로 공유하는 것이 편함
SEARCH STACK OVERFLOW버튼을 통해 스택오버플로우에 검색해 주는 기능을 제공
구글 드라이브와 연동하기
# 구글 드라이브 연결을 위한 기본 세팅!pip install -U -q PyDrivefrom pydrive.auth import GoogleAuthfrom pydrive.drive import GoogleDrivefrom google.colab import authfrom oauth2client.client import GoogleCredentials# Authenticate and create the PyDrive client.auth.authenticate_user()gauth = GoogleAuth()gauth.credentials = GoogleCredentials.get_application_default()drive = GoogleDrive(gauth)- 링크 타고 들어가서 verification code를 복사한 뒤 입력창에 넣어 줌
id로 실제 파일 불러오기
# 문서 ID로 실제 파일 불러오는 법## https://drive.google.com/open?id=1VBre-j1bHeQ4uvTTygVzuEO0sKcZGmy6## https://drive.google.com/file/d/ 19DhEWDDjHja98ciElpIMM8r05Ye-Z2Np /view?usp=sharingrawdata_downloaded = drive.CreateFile({'id': '1CIdStWHTYS0k_ZH_miY2vlHHQHO82MWc'})rawdata_downloaded.GetContentFile('testko00.csv')
Python
Python
- 1991년 프로그래머인 귀도 반 로섬(Guido van Rossum)이 발표한 고급 프로그래밍 언어
- 플랫폼에 독립적이며 인터프리터식, 객체지향적, 동적 타이핑(dynamically typed) 대화형 언어
- 패키지(package)
- 각종 변수, 함수, 클래스를 포함하는 파일인 모듈(module)의 집합
- 간단한 명령어로 다양한 오픈소스 패키지를 불러와 활용이 가능함
예) 데이터 관리 툴인 pandas, 한국어 분석 패키지인 konlpy, 중국어 분석 패키지인 jieba, 딥러닝 패키지인 TensorFlow
- 변수, 조건, 반복을 조합하는 것이 프로그래밍
- 1991년 프로그래머인 귀도 반 로섬(Guido van Rossum)이 발표한 고급 프로그래밍 언어
konlpy
한국어 정보 처리를 위한 파이썬 패키지 #
# konlpy 설치!pip install konlpyfrom konlpy.tag import Kkmakkma = Kkma()# 문장 단위 분리print(kkma.sentences(u'네, 안녕하세요. 반갑습니다. 다음에 또 만나요.'))# 명사만 추출print(kkma.nouns(u'질문이나 건의사항은 깃헙 이슈 트래커에 남겨주세요.'))# 품사 태깅 (POS tagging)print(kkma.pos(u'여러분 이 수업이 너무 어렵지는 않나요? 이해가 되시나요?'))# ['네, 안녕하세요.', '반갑습니다.', '다음에 또 만나요.']# ['질문', '건의', '건의사항', '사항', '깃헙', '이슈', '트래커']# [('여러분', 'NP'), ('이', 'MDT'), ('수업', 'NNG'), ('이', 'JKS'), ('너무', 'MAG'), ('어렵', 'VA'), ('지', 'ECD'), ('는', 'JX'), ('않', 'VXV'), ('나요', 'EFQ'), ('?', 'SF'), ('이해', 'NNG'), ('가', 'JKC'), ('되', 'VV'), ('시', 'EPH'), ('나요', 'EFQ'), ('?', 'SF')]
과제 제출
- 실습 파일 교수님께 공유하고 구글 드라이브 과제 폴더에 개인 폴더 만들어 업로드하기
2-3주차. 형태소 분석 개론
언어 분석 패키지
- KoNLPy
- 한국어 정보 처리를 위한 파이썬 패키지
- 5종의 형태소 분석기 내장
- Hannanum
- KAIST Semantic Web Research Center 개발한 형태소 분석기
- Kkma (꼬꼬마)
- 서울대학교 IDS(Intelligent Data Systems) 연구실에서 개발한 형태소 분석기
ntags = 56- 딕셔너리 업데이트가 잘 안 되어 있음 (~2007)
- Komoran
- 최근에는 잘 안 씀
- Mecab
- 일본어 형태소 분석기를 개량한 Mecab-ko
ntags = 43- 성능이 전체적으로 무난함
- Okt (Open Korean Text = Twitter)
- 트위터를 분석하기 위해 만들어진, 요즘 핫한 형태소 분석기
- 트위터에서 만든 오픈소스 한국어 처리기인 twitter-korean-text를 이어받아 만들고 있는 프로젝트
- 사전마다 품사를 나누는 기준(품사 분류 체계)이 다른데, Okt가 가장 이질적임
ntags = 19로, 까다로운 품사 분류는 간소하게 뭉뚱그림
- 트위터를 분석하기 위해 만들어진, 요즘 핫한 형태소 분석기
- Hannanum
- 형태소 분석기 비교

언어 분석
N-gram 분석 맛보기
#@title N-Gram - 띄어쓰기 기준 분리문장 = '' #@param {type: "string"}NGram크기 = "" #@param ["1", "2", "3", "4", "5", "6"] {allow-input: true}from nltk import ngramsngrams = ngrams(문장.split(), int(NGram크기))for grams in ngrams:print(grams)형태소 분석 맛보기 (kkma)
#@title 한국어 형태소 분석 - konlpy(kkma)한국어문장 = '\uB098\uB294 \uC544\uBA54\uB9AC\uCE74\uB178\uAC00 \uC88B\uC544.' #@param {type: "string"}# konlpy 설치하기 ## https://data1000.tistory.com/33!pip3 install jpype1==0.7.0!pip3 install konlpyfrom IPython.display import clear_outputclear_output()from konlpy.tag import Kkmafrom konlpy.utils import pprintkkma = Kkma()print(" ")print("###문장 분리###")print(kkma.sentences(한국어문장))print(" ")print("###명사 추출###")print(kkma.nouns(한국어문장))print(" ")print("###형태소 분리###")print(kkma.morphs(한국어문장))print(" ")print("###품사 태깅###")print(kkma.pos(한국어문장))형태소 분석 맛보기 (okt)
#@title 한국어 형태소 분석 - konlpy(okt=twitter)한국어문장 = '\uB098\uB294 \uC544\uBA54\uB9AC\uCE74\uB178\uAC00 \uC88B\uC544.' #@param {type: "string"}# konlpy 설치하기 ## https://data1000.tistory.com/33!pip3 install jpype1==0.7.0!pip3 install konlpyfrom IPython.display import clear_outputclear_output()from konlpy.tag import Oktfrom konlpy.utils import pprintokt = Okt()print(" ")print("###명사 추출###")print(okt.nouns(한국어문장))print(" ")print("###형태소 분리###")print(okt.morphs(한국어문장))print(" ")print("###품사 태깅###")print(okt.pos(한국어문장))03_언어분석_한국어_기본.ipynb- rawdata.txt 파일을 가공하고 csv 파일로 저장
03_02_언어분석_한국어_심화.ipynb- 언어분석 한국어 기본 파일의 소스 코드가 직접 노출된 파일
Excel은 생각 이상으로 좋은 데이터 분석 툴
시각화
- wordcloud
- 간단한 시각화 방법
- 띄어쓰기 단위로 단어 인식
- Word Cloud Generator
실습) 노무현 대통령의 명사 워드 클라우드
- 간단한 시각화 방법
해석
- 상대 빈도(relative frequency)
- 단어의 빈도가 같아도, 의미는 다를 수 있음
- 전체 텍스트 중 특정 단어가 얼마나 나오는지가 중요
- 따라서 상대 빈도를 살펴봐야 함
SUMIF: 엑셀, 조건에 맞는 데이터의 합을 구하기
- 단어의 빈도가 같아도, 의미는 다를 수 있음
- 피벗(pivot)
- 데이터를 요약하는 통계표
- 요약에는 합계, 평균, 기타 통계가 포함될 수 있으며 피벗 테이블이 이들을 의미 있는 방식으로 함께 묶어 준다.
실습) 동사로 필터링한 피벗 테이블
- 박근혜 대통령은 마침표(.)를 적게 사용함
- 대체로 문장이 간결하지 못하고 장황함
- 노무현 대통령은 '동북아'를 많이 언급함
- 동북아 균형자론
- 문재인 대통령은 '대한민국'을 많이 언급한 대신, '국가', '세계', '사회'는 거의 언급하지 않음
- 사회 분열이 상당한 시점이기에 일부러 언급을 피함
- 국내 이슈에 집중하고 국민의 단합을 강조
- 박근혜 대통령은 마침표(.)를 적게 사용함
- 어떻게 해석할 것인가?
- raw data 텍스트가 어떻게 만들어졌는지 상시 유념해야 함
- 취임사는 정치적 의도를 철저하게 내포한 텍스트
- 텍스트에 내재된 의도를 분명히 파악하지 못하고 수치에만 매달리면 오류를 범할 수 있음
- 나만의 해석을 꼭 가미해야 함
- '미래 지향적 단어'와 같은 본인만의 범주화도 가능함
- 결론
- 해석은 도메인 지식이 필요하다.
- 도메인 지식 유무에 따라 같은 자료를 놓고도 다른 것을 볼 수 있다.
- 도메인 지식이 없는 방면보다는 있는 방면을 연구 주제로 삼자.
- 해석은 도메인 지식이 필요하다.
- raw data 텍스트가 어떻게 만들어졌는지 상시 유념해야 함
과제
- 2주차 : 01, 02 파일 문장을 바꿔서 실행해 보고 공유 및 업로드
- 3주차 : 역대 대통령 취임사 데이터를 내 마음대로 분석해 보고 xlsx 파일 업로드 (해석과 발표)
4주차. N-gram
- 사용처
- 고전 한문, 옛 한글의 경우 아직도 N-gram을 사용한다.
- 1-gram(unigram)
- 근대 쪽 텍스트도 어쩔 수 없이 N-gram을 써야 하는 경우가 많다.
- 한글, 옛 한글, 일본어가 섞여 있는 텍스트
- 어법이 다른 경우도 빈번함
- 과거 텍스트로 거슬러 올라갈수록 형태소 분석기가 무용해짐
- 고전 한문, 옛 한글의 경우 아직도 N-gram을 사용한다.
N-gram 실습
04_N-Gram.ipynb참고- tsv로 다운받기그룹통합.to_csv(str(NGram크기)+'gram_분석결과.csv', header='true', sep='\t', encoding='utf-8')
- N-gram 실습 결과
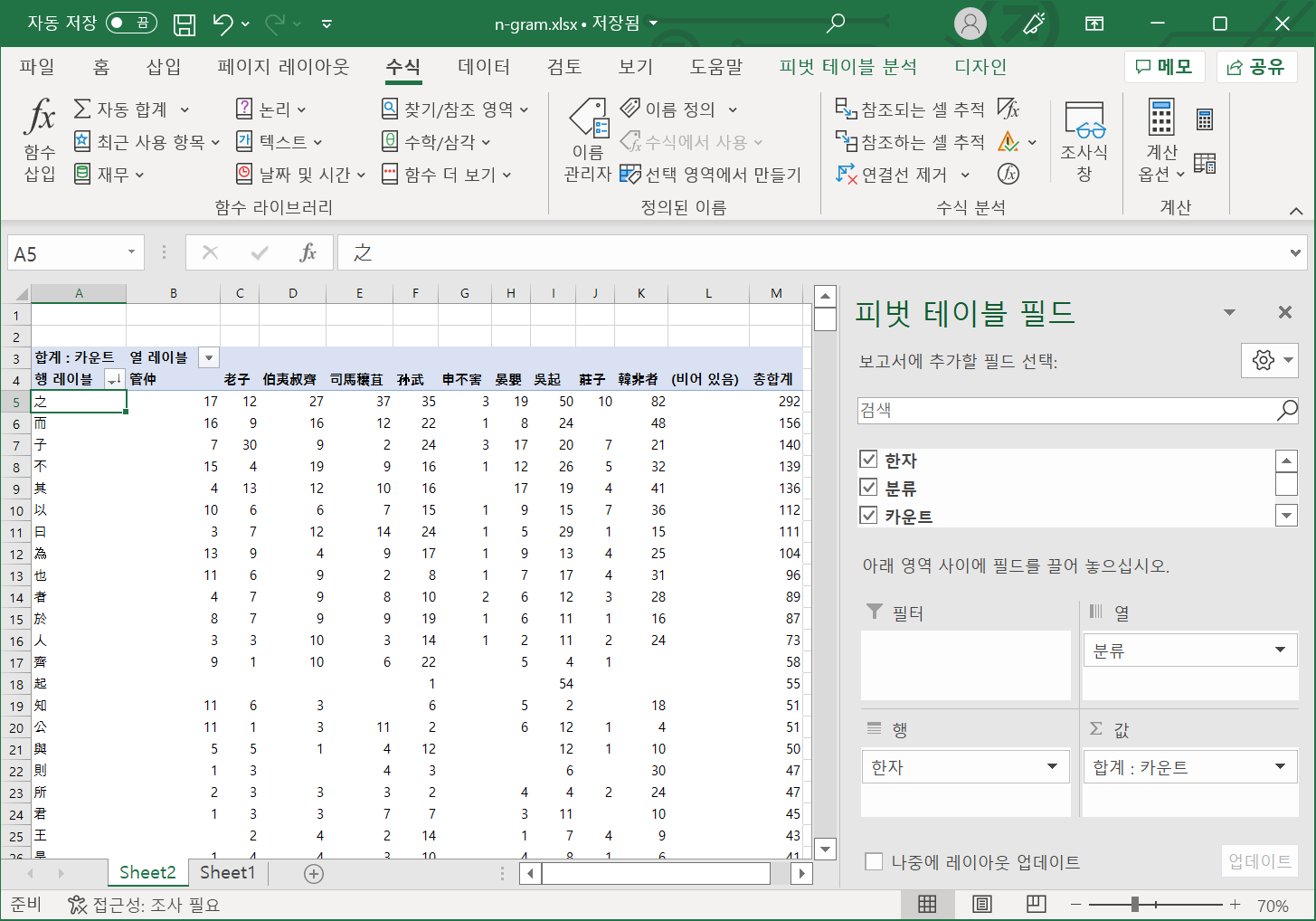
- tsv로 다운받기
4주차. Word2Vec
- 임베딩(embedding)
- 원-핫 인코딩(one-hot encoding)
- 있으면 1, 없으면 0
- Word2Vec
- 원-핫 인코딩(one-hot encoding)
- Word2Vec
- 단어 각각이 벡터 공간에서 좌표 값을 가짐
- 상대적인 좌표 거리가 의미를 가짐
- 의미 연산이 가능함
- 분산 의미(distributional semantics)
예) 최상의 __를 얻으리라.앎은 자연스러우나,똥은 어색함- 의미가 분산되어 있기 때문
- 저절로 공기어 분석이 이루어짐
- 차원(dimension)
- 기저 벡터의 갯수
- 즉, 3차원 공간을 구성하는 데 3개의 기저 벡터가 필요하다는 의미
- 차원이 높아질수록 대상을 정밀하게 분석할 수 있음
- Word2Vec은 100차원을 넘기면 효율성 증가가 더뎌짐
- 보통 100차원을 default로 하여 수행함
- 차원 축소(dimension reduction)
- 100차원으로 수행했어도 2차원으로 축소할 수 있음
- 무조건 왜곡이 존재한다는 문제점이 있음
- 논문을 쓰는 입장에서, 2차원으로 시각화하는 경우가 대부분임
예) PCA
- 100차원으로 수행했어도 2차원으로 축소할 수 있음
- 기저 벡터의 갯수
- 윈도우(window)
- 중심 단어를 예측하기 위해 앞, 뒤로 몇 개의 단어를 볼지 정해 준 범위

- 중심 단어를 예측하기 위해 앞, 뒤로 몇 개의 단어를 볼지 정해 준 범위
- 학습 방식
- CBOW(Continuous Bag of Words) : 주변에 있는 단어들을 입력으로 중간에 있는 단어들을 예측하는 방법
- Skip-Gram : 중간에 있는 단어들을 입력으로 주변 단어들을 예측하는 방법 (보통 성능이 더 좋음)
- wevi: word embedding visual inspector
- 1주차 강의 참고할 것
- 단어 각각이 벡터 공간에서 좌표 값을 가짐
- 클러스터링(clustering)
- 유사한 속성들을 갖는 데이터를 일정한 수의 군집으로 그룹핑하는 비지도 학습
- k-means clustering
- Embedding Projector
- 데이터를 분석하고 서로 관련있는 임베딩 값을 보기 위한 시각화 도구

- 사용하기
- 데이터를 분석하고 서로 관련있는 임베딩 값을 보기 위한 시각화 도구
- Doc2vec
- 문서를 Vector로 변환
Word2Vec 실습
05_워드임베딩_Word2Vec.ipynb참고
과제
- 워드임베딩 전체를 실행해 보고, 다른 개별 단어, 다른 패러미터를 넣어 테스트해 본 뒤 colab 파일 제출하기
5주차. 사회 네트워크 분석(SNA)
- 사회 연결망 분석(Social Network Analysis)
- 사회 연결망 데이터를 활용하여 사회 연결망과 사회 구조 등을 사회 과학적으로 분석하는 방법론
- 네트워크 분석과 네트워크 시각화는 다르다!!
- 시각화는 분석의 목적이 아니다.
- 사회 연결망(Social Network)
- 기초 개념
- 노드(node) : 점/대상/사람
- 링크(link) : 선/연결/관계
- 중심성
- Degree centrality(연결 중심성)

- Hub(마당발)
- 일차적으로 연결되는 노드의 수
- Betweeness centrality(매개 중심성)

- Linker(연결자)
- 두 그룹을 연결해 주는 노드
- Closeness centrality(근접 중심성)
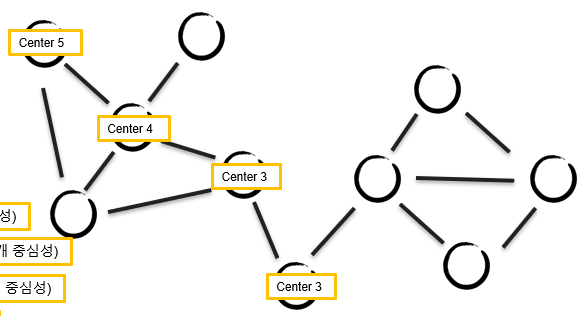
- Center(중심자)
- 전파력 (center 3이 코로나 확진일 경우, 전체로 전파되는 데 3번이면 됨)
- 근접 중심성이 클수록 빠르게 확산 가능
- Eigenvector Centrality(EC, 고유벡터 중심성)

- 종합 점수
예) 그래프의 중심성
- Degree centrality(연결 중심성)
- 기초 개념
- 네트워크 표현 방법

- 엣지 리스트(edge list)
- 인접 행렬(adjacency matrix)
- 그래프(graph)
- 참고 문헌
- 존 스콧슨, 소셜 네트워크 분석
- 이수상, 네트워크 분석 방법론
- SNA 데이터 사례
- 구운몽 - 대화 네트워크 (다중 대상의 경우)(^.*?) (\t) (.*?) (,) (.*?$)\1
- '용왕, 선녀' 같은 데이터 전처리
- Korea DH 유튜브 채널
- 구운몽 - 대화 네트워크 (다중 대상의 경우)
Gephi
- Gephi is the leading visualization and exploration software for all kinds of graphs and networks.
- 무료, 간단한 사용법, 다양한 옵션
- 현재 0.92 version
- 설치 오류 : Cannot find Java 1.8 or higher.
- java 설치
- jdk(Java Development Kit)
- java를 사용하기 위한 java용 SDK(software development kit)
- 즉, java 환경에서 돌아가는 프로그램을 개발하는 데 필요한 툴들을 모아 놓은 소프트웨어 패키지
- jdk는 jre를 포함한다.
- java를 사용하기 위한 java용 SDK(software development kit)
- jre(Java Runtime Environment)
- java를 동작시키기 위한 실행 환경
- jdk(Java Development Kit)
- java 설치
- 이후 새로운 version이 출시될 예정
- 설치 오류 : Cannot find Java 1.8 or higher.
- Gephi 사용법
- rawdata 구축
- 수업 때는 보통 구글 설문으로 '본인 이름', '친한 사람 이름1', '친한 사람 이름2' 항목 제작하여 배포

- Source, Taget으로 컬럼명 변환
- 친한 사람 2도 Taget 하단에 붙여 넣기
- 수업 때는 보통 구글 설문으로 '본인 이름', '친한 사람 이름1', '친한 사람 이름2' 항목 제작하여 배포
- Data Laboratory
- Gephi - Data Laboratory - Import Spreadsheet

- Graph type

- Gephi - Data Laboratory - Import Spreadsheet
- Overview
- 노드 label 보기
- Data Labaratory - Copy data to other column - id 값을 Label에 붙여 넣기 - Overview 하단의 T 버튼 - 폰트 바탕
- Layout

- Stastistics

- 다양한 분석 도구 제공
- Appearance
- Node, Edge
- Color, Size : 노드 색, 크기 설정
- Partition - Modularity Class : 모듈별 색 구분 설정
- Node, Edge
- 노드 label 보기
- Preview
- 출판 논문에 싣을 용도의 고해상도 이미지 추출 가능
- rawdata 구축
기타 툴
- UciNet : 무료, 전통, 대용량 데이터 처리에 용이, 낮은 편의성
- NetMiner : 유료, 한국어 지원, 기능 빵빵
- Pajek : 무료, 전통, 시각화도 나름
- NodeXL : 무료, 간단한 분석에 유용
과제
- ppt 보고 Gephi 실습해 보기
6주차. 딥러닝 분석 개론
- Teachable Machine

- Original data
- Training data
- Training data : 학습용
- Validation data : 모의고사
- Testing data : 검증용
- Training data
- 활성화 함수(activation function)
- 옵티마이저(optimizer)

- 미니 배치(mini-batch) : 데이터 셋을 batch 사이즈 크기로 쪼개서 학습

- 1 Epoch : 모든 데이터 셋을 한 번 학습
- 1 iteration : batch 하나를 1회 학습
- NAS(Neural Architecture Search)
- 알아서 세팅
- CNN(Convolutional Neural Networks)
- 이미지 처리
- 풀링(pooling)
- 스트라이드(stride)
- 패딩(padding) : 이미지 외곽에 임의의 값을 넣어서 계산할 수 있게 해 주는 과정
- 플래튼(flatten) : 2차원을 1차원으로 축소
- RNN(Recurrent Neural Network)
- 재귀 신경망
- 역전파(backpropagation)
- 순서(sequence) 기억 가능
- 비정형 데이터 처리에 좋음
- LSTM(Long Short-Term Memory)
- RNN보다 기억력 강화
- seq2seq(Sequence-to-Sequence)
- 문장 생성
- Encoder + Decoder
- Attention
- 중요 요소 책정
- Transformer
- RNN, LSTM은 순서가 있어서 병렬 처리가 어려움
- 순서가 아닌 관계로 회귀
- Encoder
- BERT : 이해 O, 생성 X, multilingual 버전 지원
- koBERT : 한국어 베이스 BERT, SKT에서 구축
- krBERT : 한국어 베이스 BERT, 서울대에서 구축
- Decoder
- GPT : 이해 X, 생성 O
- Pre-training model의 필요성
- 아직 많이 공개돼 있음
과제
- BERT 돌려보고 업로드
- 샘플 데이터 5줄 만들어서 제출
Edit this page
Last updated on 4/13/2022